
Our Social World as a Distributed System
Preparing to design an AI-powered substitute

In the next cluster of posts, I’ll repeatedly apply analogies to move back-and-forth between familiar computer systems and the broader world, including human society. I hope each transition will add more insight. My first goal, in this post and the next one, is to see how we can understand what civilization “is really doing” as a system for computation. Then the next few posts introduce key technologies for working more effectively in artificial systems that we design deliberately.
Basics of Distributed Systems
Distributed systems are a key technique for scaling use of computers across our society. The main goal of this post is to review distributed systems and start thinking about analogies to human society.
Let me use a running example to illustrate the key advantages and techniques of distributed computing. It sure is hard lately to keep up with all of the new developments and outright hype around AI. Naturally the Silicon Valley approach is to build an AI product that tracks these developments by reading lots of web sites. The trouble is that there may not be a single computer with enough power to avoid falling behind! No problem: we can put multiple servers to use, to achieve our goal of performance scaling, improving throughput (total amount of work a system can do at once).
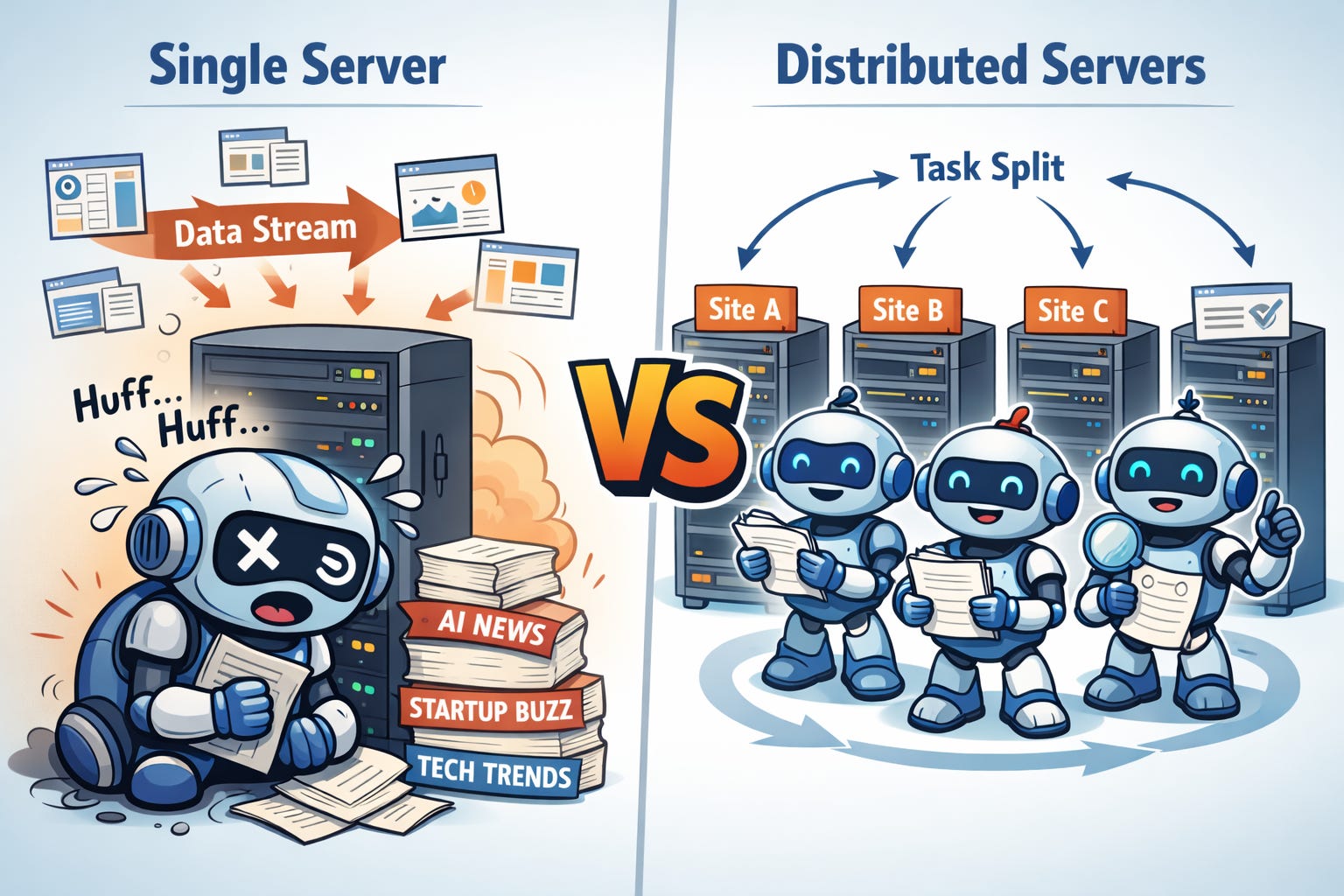
Our AI tracker is accumulating insights that many humans are eager to access. Unfortunately, those humans are distributed across the globe, and it takes time for a human to access data stored across the world. The speed of light is (probably?) a fundamental limit to communication, and other delays are introduced by inefficiencies in specific systems. Hence the value of georeplication, where data are spread across computer systems in space, even intentionally duplicating some data on multiple nodes. Now users can access the replicas that are closest to them, reducing latency.

Redundant storage of data has other benefits, too. Consider also fault tolerance, the design of systems to tolerate failures of some of their parts. If one of the servers stops functioning, other servers can pick up the slack. So long as every important piece of data was copied on at least two servers, we can tolerate the failure of a single node. With more data replication, we can tolerate more failures.

Let’s take stock of the essentials of distributed systems so far. Compared to the more tightly integrated computer systems that we discussed in the first post, two difference stand out.
The parts of the system are far-enough-away from each other in space that we really notice communication delays.
There are enough distinct parts of the system that we should plan for partial failures, where some nodes fail but others should continue the work by themselves.
Even computer systems that we don’t call “distributed” have failures of their subparts, with a classic example being a hard-disk crash. When a hard drive fails in a data center, a technician might jump in to replace it, but we generally tolerate the whole attached computer being down until that maintenance is complete. In contrast, distributed systems tend to notice and react to failures without human intervention.
Distribution Across Trust Boundaries
The story gets more interesting as we start thinking about the different computers being run by different parties that don’t trust each other. Another way to put it is that the owners of different servers may face misaligned incentives with each other. There can be zero-sum dynamics where one party benefits at the expense of another.
For our running example, imagine that so much computing power is needed that the work must be split across servers run by different companies. Those companies may see each other as direct competitors and worry about intentional provision of faulty results, to sabotage each other. Or they just may worry about free-rider problems where companies slack off and try to trick others into doing almost all of the work. As an example, one broad concern in this kind of situation is integrity, enforcing that data represent the right information, influenced in proper ways by authorized parties. Our running example includes a requirement that results of analysis on what’s going on with AI should be roughly consistent with the true state of the world. In this distributed system, it makes sense for companies to accept analysis from their partners but also audit those results somehow. They pay extra computational cost that (1) should be much less than the cost of just doing the analysis individually but also (2) pays off in detecting at least blatant efforts by so-called partners to provide false or misleading information.

These complications can arise in settings that feel like games where everyone is playing by clear rules with fixed “winning conditions,” but the existence of multiple players orients the shared incentive structure in different directions across the system. Cybersecurity introduces additional twists: some of the nodes in the system may be compromised and “tricked” into behaving differently. We may also worry that the genuine owners of some nodes decide for whatever reasons to stop playing by the shared rules, beginning to behave in arbitrarily disruptive ways. Many distributed systems are also designed to tolerate failures of this kind, and that design quality is Byzantine fault tolerance.

This last part of the discussion added two important fundamental properties we often worry about in distributed systems.
Nodes may have different owners who are competing with each other in some dimensions at the same time as they cooperate in others.
Nodes may fail in ways that don’t just look like disappearing but instead cause arbitrarily bad behavior.
Connecting to our Human Society
The conventions of cooperation underlying a distributed system are called a protocol. I now want to start turning our attention toward analyzing the way our human world works, considered as a distributed protocol. With a good understanding of what is going on, we can think like engineering consultants called in to analyze a dusty legacy system, reverse-engineering it partly by understanding the intentions of its original designers, which roughly speaking stands for evolution here. Then we’ll get to imagining how we could realize the appropriate goals even better using technical ideas.
First, we can sanity-check the idea of seeing human society as a distributed system. The nodes of the system are the individual people, naturally. What about the four fundamental challenges we talked through?
There are certainly communication delays between people coordinating on projects, scaling with geographic distance.
Partial failures can show up for reasons from inherently flaky coworkers to natural disasters.
Humans form organizations that compete with each other.
People can exhibit arbitrarily bad behavior, for reasons ranging from pranking each other to malicious intent.
So far so good. Now let’s see if we can draw some preliminary conclusions about the cognition that we’re used to, by analogy to the computer systems we’ve discussed for most of this post. One important principle of computer-system design is layering, where complex systems are broken up into pieces that stack on top of each other, each layer taking the lower ones for granted and thus enjoying simpler implementation. Let’s think about a simple decomposition into just two layers: a local layer and a distributed layer. The former uses data structures and algorithms written with no concern for e.g. portions of a computer failing. Then the distributed protocol is written using those local features for decision-making that happens on individual nodes, in support of the broader cooperation.
I don’t want to push my luck with the length of this post, so we’ll have to wait for most tracing-through of consequences of this perspective. However, I’ll slide in here a little speculative warmup. Construal level theory is a psychological theory that I first learned about in the blog Overcoming Bias. The Wikipedia article I cited says “the core idea of CLT is that the more distant an object is from the individual, the more abstract it will be thought of, while the closer the object is, the more concretely it will be thought of.” Upshots include that we think in grand terms about ideas like the future of civilization and in more-concrete terms about how we should organize our lives for productivity on a daily basis. It seems a little strange that our brains would work that way. Why should different scales be linked to each other?
Let’s think back to our discussion of consciousness, where I argued that some fundamental-seeming words actually refer to pieces of mental hardware that we all share, or more properly to the kinds of decisions that those hardware blocks make for us. What if our brains follow computer systems in being organized fundamentally into layers for local and distributed computation, where distribution is about social coordination? Then it would make sense why clusters of concepts are associated with the two modes of near and far: near-mode topics should be routed to the hardware for local computation, and far-mode topics should be routed to the hardware for distributed computation (the local parts of implementing distributed protocols). At some level, this behavior would be no more mysterious than a CPU sending addition requests to an addition circuit and multiplication requests to a multiplication circuit. We are, of course, talking about much-more-versatile mental circuitry, but the analogy may nonetheless prove useful.
The next post will suggest one important protocol that arguably is supported by hardware in all of our heads. (You’ll just have to wait in suspense for now!) Then we’ll think about what higher goals that protocol serves and which techniques from computing can help us reach them even more effectively, as we design artificially intelligent systems.