
What Makes Language Processing Hard?
And how can we protect our AI systems from those challenges?

There’s a certain framing that’s taken for granted in almost all discussions of AI progress. Different cognitive tasks are familiar to us because we humans find it necessary to tackle them regularly. We can make a list of tasks ranked by importance in our economies and cultures. Then we can start measuring AI’s progress by how well it does on the tasks we have listed.
However, the last post on codesign suggested thinking carefully about how a shift to artificial intelligence is a good opportunity to redesign more of the way the world works. Some familiar problems are hard because of reasons that we have control over, so why not exercise those levers? I’m now going to use the example of natural language to illustrate the same pattern. Our discussion will generalize to other parts of our human world produced by evolution (some to be covered in future posts), as I highlight two aspects of our evolutionary history that systematically produced methods that are poor fits for next-generation systems. Those two properties are that evolution moves slowly and devotes significant resources to signaling.
The conclusion will be that natural language is an unnecessarily clunky interface for upcoming AI systems, and we should do better. It also happens that natural language is central to the current revolution in generative AI. Most of us were shocked by the release of ChatGPT, a powerful large language model that developed apparent broad savvy about our world through training on as many documents as OpenAI could find online. No one (or almost no one?) was planning ahead for a future of educating AIs in producing all of these documents, but it turns out that an extremely effective way to learn about the world is to find patterns that were implicit in writing about different aspects of that world. As I unspool my perspective in this blog, I’ll explain how we may be able to take inspiration from this overwhelming success but do better (with an important role for codesign), perhaps even without the need for large amounts of training data.
Evolution Moves Slowly
Here’s an example from a fun genre that gets decent coverage in mainstream media. Consider the 2017 legal case O’Connor v. Oakhurst Dairy. Delivery drivers had a disagreement with their employers about the wording of a law controlling overtime. The problematic phrase was “canning, processing, preserving, freezing, drying, marketing, storing, packing for shipment or distribution of.” Clearly this wording spells out a nontrivial list of activities, but exactly how long is the list? Does it contain eight or nine items? The answer depends on whether we adopt the Oxford comma! In other words, should the “or” at the end have a comma before it to indicate that we are about to give the last item of the long list? Or are we actually spelling out a nested list as an element of the outer list?
Clearly the phrase declares that packing for shipment is in-scope. The question is whether packing for distribution is in-scope, too. Maybe only distribution but not packing for distribution qualifies. We get a different “obvious” answer depending on whether we adopt the Oxford comma. An appeals court ruled that Oxford commas are presumed in the law, thus distribution was not a core job duty of delivery drivers, and they are entitled to overtime for it.
Now, from context, it is clearly bonkers to imagine that we spell out a long list of duties for delivery drivers and omit distribution. However, an important benefit of the law is being explicit about rules to avoid problems from alternative interpretations by readers with different contexts. We know that our natural language is full of ambiguity and are used to navigating it, but examples like the victorious delivery drivers show how we can still run into trouble from ambiguity. The legal profession has developed norms to try to minimize ambiguities, but mistakes slip through.
I’m going to use language ambiguity to illustrate the broader pattern of evolution moving so slowly that key features don’t adapt to changes in the way the world works. Any instance of this pattern needs to specify two key parameters. First, we need the way things used to be: humans lived in hunter-gatherer bands of at most a few hundred people. Then, we need how things changed: humans can participate in a globalized economy and culture with billions of people.
Now for more detail on the way things used to be, in this case with anatomically modern humans, who appeared hundreds of thousands of years ago. They lived in social groups that are small by today’s standards, and they rarely interacted with people from other groups. As a result, group members shared a lot of context: models of the world and which ideas are worth communicating. Context allows resolution of ambiguity. In fact, communication can be a lot more efficient by taking advantage of ambiguity, when there is enough shared context, an intuitive proposition that some formal studies have confirmed. So, let’s give evolution the benefit of the doubt and assume a language system that worked well for humans 100,000 years ago, naturally taking advantage of ambiguity.
Fast-forward to today where people communicate across vastly larger spans of space, time, and culture. There are many opportunities to talk or write to someone with very different context, and the consequences of misunderstanding can be unpleasant – by enough to constitute a real disadvantage for survival or reproduction. Unfortunately, evolution hasn’t had time to catch up, because it moves much more slowly than the rate of cultural change. We believe humans only settled down in groups of more than a few hundred people with the rise of agriculture, on the order of 10,000 years ago. The total time since then is short compared to how quickly evolution tends to work.
We’ll return in a later post to why natural evolution is so slow, but for now, the following picture helps us understand why language is “stuck” being ambiguous and hazardous to use across contexts. Fundamentally, cultural “evolution” proceeds more quickly than narrowly biological evolution, and the gap between the two grows with time. I’m even giving evolution an unfair advantage here, since experts seem to agree that almost nothing has changed about our language-processing circuitry in the last 100,000 years (see The Language Instinct making the case for a broad audience), but I’m drawing slow progress anyway.
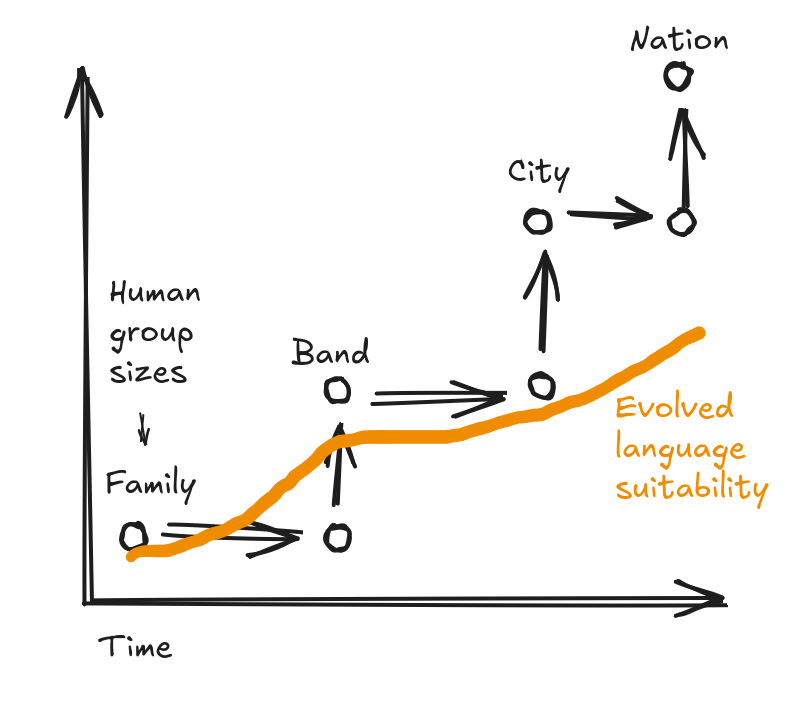
We expect to see the same kind of gap between a system with almost any level of deliberate ongoing design and another system that only progresses through evolutionary selection.
Evolution Has Diverted Resources to Signaling
We’ve just been discussing how, when we give evolution the benefit of the doubt in aiming for “the right” goals, it can nonetheless be inefficient in attaining them. But could it also happen that evolution is implicitly working toward some goal that is at-odds with what we say we want? Language provides a good example of such a pattern, within the broader phenomenon of signaling. I first learned about this perspective via evolutionary psychology from popular-science books like The Moral Animal and The Blank Slate (which are some of my favorite nonfiction recommendations, broadly).
The classic example of signaling is the peacock’s tail. These male birds develop elaborate tails that really interfere with their daily business of survival. The idea behind (evolutionary) signaling is that getting in the way is the point: the peacock with the most over-the-top tail sends the strongest signal to the peahen (his female counterpart) that he is really good at survival. The peahens probably don’t have the cognitive capacity to go through that reasoning deliberately. However, in the distant evolutionary past, it turned out that a good heuristic for identifying prime mates was noticing tails of certain shapes and sizes (modest by today’s standards). Once this preference existed, runaway selection could amplify the extremity of the trait through sexual selection, where animals that manage to appeal more to potential mates reproduce more, and thus their genes spread through populations.

Now think about language. Besides the immediately obvious purposes like conveying factual information efficiently, we humans also use language to signal competence to potential mates or coalition partners. Both generating and consuming language are chances to show off. For instance, politicians demonstrate that they are worthy of election by giving speeches where they show off not just knowledge of “the issues” but also general verbal fluency – picking words and phrases just fancy-enough to land with their audiences without going over anyone’s head. Or maybe they pull off the even-trickier feat of hiding messages for brainier listeners while staying appealing to the broad electorate. Audience members can then show off by discreetly letting each other know that they extracted the secret messages.
Dense books or blog posts are also a great chance for signaling in both directions. Authors get to show off how well they can write, and readers can show up and post comments to show how they have carried out original analysis that adds value and then explained it well.

The Upshot for AI and Natural Language
So natural language been shaped by evolutionary forces that move slowly and thus haven’t updated it for the needs of the modern world. If we think examples of confusing legal language are funny, we’re headed toward even bigger snafus as AI agents act on our behalfs and may misunderstand each other in catastrophic ways that humans don’t have any chance to catch. E.g. imagine a safety-inspector agent interacting with an agent representing a project to construct a bridge (maybe even autonomously overnight) that turns out to be safe for trucks but not pedestrians, because of disagreement on what “safe” means. Not only that, but natural language is hard on-purpose due to evolutionary pressure from signaling. It is usually a bad engineering decision to tackle problems that are hard on-purpose!
There is a lot of expectation of agents doing a lot with natural language. For instance, one agent helps a job-seeker send out many resumes customized to potential employers – maybe stretching the truth a little differently for each version, depending on what is expected to appeal to different readers. Then on the other side, employers use resume-filtering agents that do their best to cut through the noise and find candidates worth interviewing. This developing arms race sounds like dystopian science fiction to me.
Let’s take a step back and adopt a codesign perspective. Language has an apparently central role in AI because of the genuinely central role it plays for us as humans. We have special hardware dedicated to language. However, the problem is that many observers don’t go far-enough in planning a future full of AI agents. The very proliferation of these alternative intelligences suggests that natural-language interfaces will become increasingly suboptimal. We should be able to provide communication styles that avoid ambiguity and are designed for simple processing (the opposite of being hard on-purpose). Heck, we should let the AIs iterate developing their own superior communication methods.
As one slightly more concrete example, we can think about agents supporting both sides of a job market. What if resumes came in a structured format with claims that are (relatively) easy to verify, say by contacting agents representing employers? With natural language, job-seekers can always claim that their false statements are actually true when read in slightly different ways. Even without the risk of inaccuracy, it’s just likely to remain much cheaper for computers to ingest and analyze simple structured data than to handle the full nuance of natural language, so we can save on compute time and power even if we ignore the vetting element.
It is important to acknowledge that there is something special about natural language today: there is so very much of it available online. The LLMs that kicked off the generative-AI revolution were trained on that body of language. It turns out that subtleties of our world are covered very well by the language people have written about that world, so all along we were creating documentation that AIs can use to learn the specifics.
OK, so if we want to maintain those advantages but avoid the ambiguity and intentional difficulty of natural language, what are our options? Can we find or generate another source of many helpful examples? Or could we even find a path to intelligence that doesn’t go through mountains of training data (almost a heretical question in Silicon Valley today!)? While we’re dreaming big, it’s worth considering whether we can even increase computational efficiency and reduce energy usage.
I’ll return to those questions eventually, but the next post will be about a similar domain where we can already see advantages from deviating from the existing linguistic training data. Instead of natural language, I’ll talk about software and programming languages, bringing us closer to what I do for a living.