
Codesign for AI and Programming
A clear case where the power of simplification is in our hands

We’ve looked at two example domains of challenges for AI: natural language, heavily tied to our evolved mental hardware; and autonomous driving, involving major pieces of manmade infrastructure. Even autonomous driving depends greatly on laws of physics that are beyond our control. Let me now consider a domain where we have extreme control over the problem context: software programming. While new software engineers face a bewildering variety of programming languages and tools, they have all been designed by people, and we can decide to redesign them. The trouble is that so much work with AI code generation is happening assuming that programming tools are frozen in place from 2022.
There is so much excitement in the air about generative AI bringing massive changes to our capabilities as a society, perhaps culminating in superintelligence that we can’t even understand. Why should we presume that a superintelligence would build software like we are used to today? Yet the AI coding agents that are deservedly spiking in popularity have a fundamental weakness: they’re trained on many examples of the software people like to write today. Coding mistakes that appear in enough places online propagate into the repertoires of AI coding tools. Staying on this trajectory can take us to some pretty absurd places.

Apologies for somewhat of an inside joke for the programmers out there. The intrepid explorers in the cartoon have used an SQL-injection attack against the superintelligence. It’s a particularly central example of a common coding mistake that can easily be perpetuated by AI that simply learns from crawling the web. SQL injections allow users to trick systems into running arbitrary instructions, which is serious-enough that it reliably makes lists of top categories of security problems. Catastrophic security vulnerabilities aside, there is more opportunity from rethinking programming and how AI can help with it.
How AI Coding Tools Work (Cartoon View)
As of this writing, AI programming assistants like Claude Code are taking the software-development world by storm. They build on general LLMs trained over many examples found online. Let’s think about what that process means as a workflow to produce coding insights and apply them to particular programming problems.
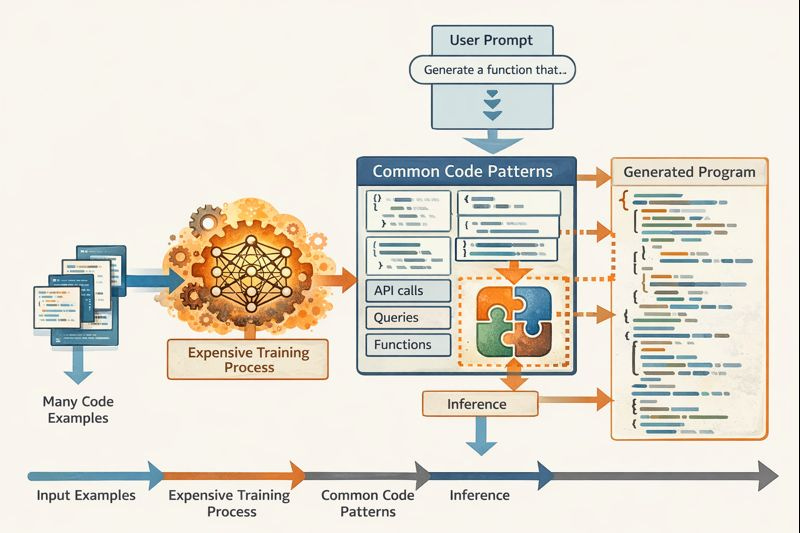
Everything starts from a large set of example code files, which can be obtained by crawling the web. They are fed into an expensive training process. One summary article paints a clear picture of tens of millions of dollars and up per training of a cutting-edge model – and the example of DeepSeek is given with such a low cost of $5.6 million that some analysts are disputing its plausibility! Nonetheless, let’s assume the effort is worthwhile for all the goodies it unlocks. Perhaps by now even just the applications in programming justify the cost.
It is important to keep in mind that LLMs, and deep neural networks in general, tend to be inscrutable to human observers. Research continues in interpretability, but generally we have very little understanding of why a neural network is able to complete certain tasks or how it is organized to support them. We can assume that frontier models contain within themselves some representations of many useful coding patterns, each generalized out of many examples.
Now consider what happens when a programmer makes a particular functionality request in English. The request can be fed into the LLM as a prompt, and the LLM can identify which coding patterns are good matches for the functionality. Now here is where we hit the part that I want to argue is deeply problematic: the LLM then stitches together code fragments representing the different patterns. They wind up combined in a kind of mush that is nontrivial reading even for expert programmers. There is probably some structure, at least implicitly, within the LLM to capture the vocabulary of coding patterns to be brought to bear, but the structure is lost during the generation of concrete programs.
Still, it’s remarkable how much these tools are already achieving. I gave Claude Sonnet 4.5 the following prompt.
Create a web app to support an elite team that responds to reports of LLMs run amok. The public should be able to submit reports of LLM incidents, and then the members of the team can triage these incidents, deciding which to respond to. It will be good to have a dashboard summarizing trends in reports. Since we’re just prototyping, it’s OK to use dummy authentication, though later we’ll want to hook into the company SSO system.
After I clarified that I wanted to use an SQL database, it completed the task. I haven’t put the resulting code through its paces, but there are about 1200 lines of code split across 12 files, taking up about 75 kilobytes. Claude needed about a minute to code it all up, which contrasts extremely favorably with the bad old days of programming before we had AI. Nonetheless, 75 kilobytes of code is a lot to take in (such AI-seeded projects often begin with bugs, including security vulnerabilities, that require expert attention to find), and it’s already for relatively simple functionality that would hardly be considered cutting-edge. Not only is the code duplicative of the many online examples that inspired it, there is also plenty of repetition of boilerplate patterns just within this small code base.
Opportunities from Structure
There are good reasons that AI coding tools are starting out working in the way I just outlined. Deep-learning systems depend on large amounts of training data, which means they are most effective on widely used programming languages, whatever their inherent merits or lack thereof. There are also significant signaling pressures toward complex programming challenges. Creators of LLMs are always looking for benchmarks to demonstrate how capable their models are, which means that, for them, difficulty of programming is a feature, not a bug. Programmers themselves appreciate the job security that has come from being able to handle difficult tasks.
However, we could step back and try to simplify. What if the workflow of AI code generation looked more like the following, where we actually leave the LLM with less work to do?
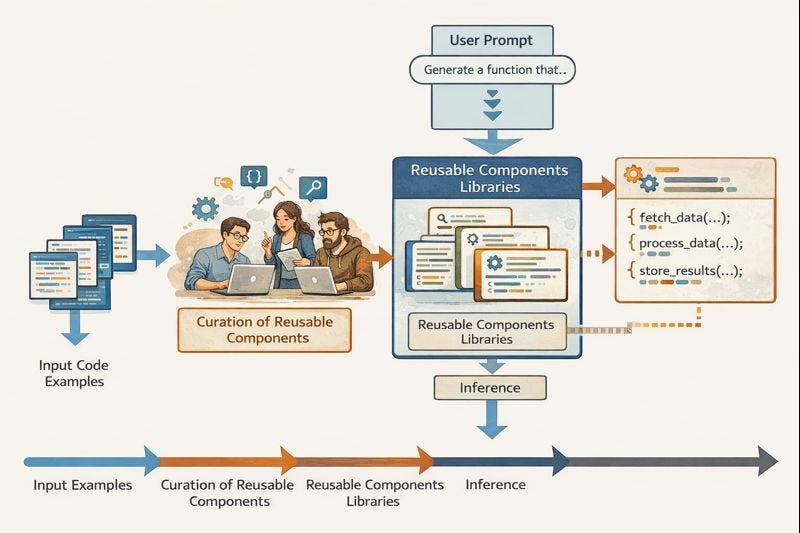
In a sense, we’re still starting with many code examples, but now they matter for influencing programmers with good taste, who manually curate a library of valuable coding patterns. These programmers might still be using AI to accelerate their work, but it is important that every pattern is embodied in a first-class reusable software component. Programmers have been required to at least pay lip service to component-based software reuse for decades, though levels of commitment and success vary widely across projects. Let’s assume we find a good crew able to curate a library of components standing for common features.
Now we can prompt an LLM with the same functionality requests as in the last scenario, but it operates rather differently. It still needs to find the most-relevant components for the task, which can work similarly to with the mainstream approach. However, now instead of dropping into our software program a pile of code for each component and mixing them all together into a soup where the components may become unrecognizable, the generated program simply references the components by name. As a result, it can be much shorter and simpler.
Let me be a little more concrete using the example of a system I’ve worked on, Nectry, a tool for creating enterprise software with a chatbot interface. I gave Nectry the same prompt as above, and it produced under 250 lines of code or about 7.5 kilobytes – so about a factor of 5 saved in lines of code and factor of 10 in total code size. The trick is that everything is expressed in our new declarative, domain-specific language NectryCore, which omits most of the tricky features of programming, only making it possible to describe how to configure components and plug them together.
The components in Nectry are also notably high-level. For instance, the example here used a component called “Approval Flow Table,” which stands for the idea of showing users a table of requests with buttons to click to approve or deny them. Now none of the code explaining such a feature from first principles needs to be included in a program. Instead, the program just mentions “Approval Flow Table” and explains how to specialize it to a scenario.
Opportunities for Guarantees
Imagine that, some way or another, an AI assistant has produced a program for us. We can subject it to testing, but testing alone is not enough to know that the code won’t misbehave in a scenario that we failed to anticipate. The costs of misbehavior can be almost arbitrarily high. Here’s one example: we are building software to support a hospital, and it deals both with highly sensitive patient medical records and with annual email blasts for charitable fundraising. It sure would be a shame if someone’s medical chart snuck into a fundraising email. It would be the kind of shame that shows up on the front page of the local newspaper. As a simpler property, let’s also think about our intention that this piece of software can’t turn off the hospital’s electrical system.
The trouble is that checking that software obeys formal requirements is notoriously difficult. The best case would be that another software program checks the program produced by AI. Unfortunately, celebrated results of computer science tell us it’s not possible (with an important caveat to come shortly). There are many programming languages, but it turns out that almost all of the widely used ones are equivalent in the sense of being Turing-complete: any program written in one of them can be translated into a functionally equivalent program in any of the others. This equivalence sounds like a relief: while programmers are known to engage in heated arguments about “the best” programming languages, the choice doesn’t seem to matter for what can be accomplished.
There’s a catch, though. Turing completeness isn’t purely a desirable club for a language to belong to. In a formal sense, automatically answering questions about the behavior of programs in these languages is impossible. Alan Turing proved that no program can accept as input arbitrary programs in a Turing-complete language and reliably tell us whether they terminate or run forever. That problem is formally undecidable. In fact, starting from the undecidability of the halting problem, we can derive that most other interesting questions about program behavior are also undecidable.
Let’s take our hospital example, in the simpler case where we want to know if a program could ever shut off the building electricity. Assume we had some systematic way to answer that question, for arbitrary program versions written in some Turing-complete language.

It turned out that we’re in big trouble. A solver for the halting problem can be built out of our solver for the could-turn-off-electricity problem. The formal reduction isn’t important for the present argument. What we need to remember is that automatically answering questions about potential behavior of programs in Turing-complete languages is extremely hard, even impossible in a certain formal sense. And, when AI delivers a program to our specifications, it would be extremely valuable to be able to check that the result met the requirements.
One solution, being actively explored by a number of teams today, is to ask AI to write not just a program but also a mathematical proof of its correctness. Then a trustworthy algorithm can validate the proof, without assuming any competence by the AI. I’ve spent most of my career working toward good tools for people to write these kinds of rigorous proofs. However, there really is no free lunch when it comes to undecidability of interesting properties of programs in Turing-complete languages (formally Rice’s theorem). The upshot for proof of program correctness is that it’s a hard problem full of nuance. This difficulty makes for another attractive target for benchmarking LLMs, but such difficulty isn’t great for helping us generate the practical programs we want. (We will still return in later posts to discussing how to scale this approach; it just isn’t the low-hanging fruit.)
Could we sidestep these difficulties? It’s always helpful to check the assumptions leading to an unpleasant conclusion, in case one assumption can actually be avoided. Here, our opportunity is to avoid Turing-complete languages. I gave the example above of the NectryCore language, which avoids most tricky features of programming, in favor of building programs out of high-level reusable components. It turns out that a variety of questions of program behavior become decidable.
For instance, above I gave an example of not wanting any information from confidential medical records to make its way into fundraising emails. This problem can be generalized into information-flow properties, limiting the influence of information inputs. Such problems turn out to be straightforward to check on programs expressed in the right high-level way. Roughly, the reason the problem is hard for Turing-complete languages is that they include features like loops and recursive functions that allow executions of arbitrary lengths, making it hard to explore all possible execution paths – in general, there are infinitely many! NectryCore programs can be checked against information-flow properties by enumerating all paths between components, which hide in their (expert-written) implementations all of the work with loops and recursion needed to bring their high-level functionality to life.
Takeaways
Programming is a great example of a highly artificial domain. We created all of its structures and invented all of its rules. We should be ruthless changing them to lower costs of software development. I admit, the techniques I highlighted were also favorites in my research community, even before AI code assistants were practical. Programs written by people were already at risk of being too hard to understand and too full of bugs. However, the case is even stronger now, as code is written by opaque AI systems that can’t be held accountable for mistakes.
In both cases, we may worry about actively malicious entities, whether human programmers or AI assistants, doing their best to hide defects in the code they write for us. I’ll have more to say about such cybersecurity challenges in later posts, but for now, the principle to keep in mind is that we owe it to ourselves to simplify the structure of programming, partly in service of establishing mathematical guarantees.
This post ends an arc of four, presenting different challenges commonly assumed for AI, analyzing different reasons that we probably don’t want to solve precisely those problems. We may not need to build conscious AIs after all; it may be worthwhile and possible to sidestep both the challenges of driving on today’s roads and the complexities of natural language; and now we started thinking about how to change programming to simplify the jobs of AI coding assistants. In the upcoming arc of four posts, I’ll step back and discuss more generally the evolutionary processes that have produced natural intelligence and some tools from computer science that should help us accelerate exploration of design spaces dramatically – with mathematical guarantees.
In regards to the cybersecurity challenges you've hinted at, I've learned that poetry and inaudible voice commands are starting to be used for injection attacks in AI systems. Poetry is highly contextual and can be used to essentially inject malicious prompts into an AI agent, while malicious voice commands can be sent over human-inaudible frequencies to inject malicious commands into voice recognizing AI agents. I'm not sure if there's a solution to such injection attacks, but they certainly present a cybersecurity challenge. ( https://medium.com/@albeeandrew/silent-sphinx-leveraging-adversarial-poetry-with-near-ultrasound-inaudible-trojan-nuit-attack-7c99980bfe53 )
I like how you're able to simplify how generative AI agents work, and it hadn't crossed my mind that these coding agents are also subject to the same mathematical proofs (and Turing completeness) as any other normal piece of software.
When ChatGPT started creating a buzz, I heard a lot of talk about how "programmers would be replaceable" given that it (and other AI agents) could just generate code. I'm glad to learn that not only will there always be a need for skilled programmers to 'check the work of an AI' (for lack of better phrasing), but there will also need to be proper computer scientists that can actually work on the 'theoretical aspect' of generative AI.
Despite the guarantee (heh) that computer scientists will always have a career, I can't help but think that the way computer science is taught may now become a bit challenging, and might have to change as a result. I'm sure it's simple enough to detect plagiarism amongst students, but now we'd have to detect plagiarism against a (or several) coding agents as well. Have there been any changes in computer science pedagogy that you've noticed since AI agents became easily accessible to students?