
Proof-Carrying Code in the Matrix
Enabling safe code-sharing among agents

We just explored one way that a single intelligence might improve itself over time, using formal verification to guarantee that all revisions remain consistent with early requirements. However, we may also expect that improving systems operate in ecosystems with others, mixing cooperation and competition, in a style related to distributed systems in mainstream computing today. I want to suggest another role for formal verification in that setting, and I’m going to start motivating it with an example from science fiction.
In a famous scene of The Matrix, Neo is plugged into a computer and “programmed” with knowledge of kung fu. Shortly after awakening, he is ready to spar effectively (in virtual reality) with his teacher. Who among us doesn’t like the idea of short-circuiting the usual way that we learn new skills?
This approach to learning new skills could be even more central to AI agents of the future, who may want to steal an idea from bacteria a la lateral gene transfer, where working individuals transfer “code” to each other. This kind of cooperative search through the space of good code could be critical to dramatic acceleration of technological progress.
Unfortunately, when we get down to planning the details, we run into some real obstacles to adoption. It’s one thing to transfer skills around within an environment where all agents trust each other, but what if we want to carry out transfers within a global (galactic?) community? How do we know that the providers of new skills have our best interests in mind and aren’t trying to overwrite our brains in ways that we would really dislike a priori?
Let’s step back and think about how conventional learning avoids these risks, consider the new hazards of streamlined virtual alternatives (and how they relate to established cybersecurity challenges), and then discuss how formal verification can help.
Learning Pathways
Our hunter-gatherer ancestors learned by watching their elders go about the business of daily life, while we are used to sitting in classrooms being instructed, but for our purposes these workflows are the same: some kind of educational experience has been designed to help viewers learn. We might abstract it into a cartoon like the following.

Sensory experience feeds into the human brain, within which decisions can be made about which purported valuable knowledge is worth believing and committing to memory. That element is personified as “The Skeptic” in the cartoon. Vetted ideas are passed off to “The Archivist,” who files the new knowledge away in the right place, amidst a system of organized knowledge that already exists, specific to the individual. Clearly we aren’t getting down nearly to the level of detail of neuroscience, but this gloss will be enough to help us think about the promise and risks of downloading skills. We need some Skeptic who can reject skills that don’t actually align with our goals, and we need a flexible Archivist who can integrate skills into an agent’s mental framework. The complexity of both tasks may account for how long it takes humans to learn adult skills, and there is reason for excitement about dramatically accelerating these stages, without giving up on their purposes.
We’re going to work our way up to proof-carrying code, an idea from formal verification that helps set up a very effective Skeptic. Consider AI agents engaged in a similar workflow. A new skill is proposed by a third party. It’s even cryptographically signed to help guarantee that it comes from the source it claims to come from. We’re starting out with only a modestly powerful Skeptic inside the learner to vet the skill, in this case by checking the cryptographic signature. (We’ll upgrade our Skeptics a bit later.) Approved skills are then integrated into larger software architectures by an Archivist.

Checking cryptographic signatures is a good start, but it leaves many supply-chain attacks still open. It may be true that the skill comes from the agent we think it comes from, but that agent is intentionally trying to subvert us. Or that true source may himself have been compromised by some attacker, who introduced a dangerous flaw. Most dangerously of all, everyone involved in this supply chain may have acted with good intentions, but someone unintentionally introduced a bug that nonetheless brings catastrophic consequences – perhaps only manifesting in rare circumstances that happen to include our own usage. Mainstream techniques for supply-chain security have rather little to say about this last risk, but we’ll cover a satisfying protection.
Let’s emphasize already the significant advantages of this style of “learning” beyond what we know from our own lives. A new skill/module can be copied verbatim into a larger software system. Instead of costly time investments in education, it becomes possible to switch out new versions constantly and instantly. In contrast to what probably happens in human learning, where one legible skill is encoded differently in each brain, probably spread across nooks and crannies of memory, the skill can be encoded as a separate module, and it remains possible to step back and understand the structure of the digital mind in terms of its cleanly separated parts. This clean separation is very helpful for quality assurance about the whole.
Still, a clean architecture full of malicious modules won’t do us much good. Luckily, there is a lot of prior art from the world of formal verification. Let’s take a look at it and how it might help with AI agents redeveloping their own code much more quickly than we’re used to.
Formal Verification and Software Supply Chains
It’s fashionable in some parts of the world of programming-languages research to disdain the JavaScript programming language and its ecosystem of web-based software, but I would like to give credit to its streamlined way of sharing software modules across web sites. A typical web application will bring in many libraries (separately published reusable code packages) just by linking to them, in the same way it might include a clickable link to another web site. That is, the library is represented as a URL from which the code can be downloaded. Standard web-security methods are used to confirm that a library really comes from the Internet site we think it does, including through use of digital signatures in HTTPS. If we worry that hosts will be sneaky in switching out legit libraries for malicious ones, we can even use an underappreciated web standard called subresource integrity to associate links with cryptographic hashes that can be used to check that we retrieve exactly the code intended by the author of a program.
It’s certainly a great start to confirm that we download the code that a specific Internet user meant to hand to us, but what if that user is malicious or just incompetent? Then we may wind up with a library entirely unfit for our purpose. This risk isn’t just of academic interest. One high-profile real-world case is the infamous event-stream incident, documented in an academic paper. In short, a new maintainer took over a popular JavaScript package and snuck in a new security vulnerability that would only manifest in relatively specific circumstances related to bitcoin. The paper authors argue that “conventional program analysis techniques would have likely missed the attack.”
However, solutions to this problem are also known, developed especially since the rise of the Internet in the 1990s. In the rest of this post, I’m going to focus on an idea called proof-carrying code, which has an interestingly broad span of different variations. (I should do a bit of “full disclosure” here around the fact that the term was introduced in the PhD thesis of George Necula, my own PhD advisor.)
What is the main idea of proof-carrying code? In theory, a smart agent receiving a software library could analyze it exhaustively to tell if it does what is expected. Unfortunately, most behavioral properties of interest are undecidable for most programming languages. Moreover, it just makes sense that the author of a library understands it better than a user of that library, so it is a missed opportunity to ask the user to analyze the library from scratch, with no guidance from the library author. What is the ultimate form of guidance? That would be a mathematical proof that the library meets specific requirements. It is an essential property of any formal proof language worth its salt that, while finding proofs may be intractable for many problems of interest, checking proofs is relatively straightforward, because proofs are basically sequences of uses of rules from a fixed vocabulary, and a checking algorithm just needs to march through the sequence and confirm each rule was used correctly. I should emphasize that here we are talking not about traditional “proofs on paper” that have required close human attention to check. Instead, we are talking about proofs represented as computer files, with carefully defined structure for predictable checking.
We do run into some of the same challenges I introduced in speculating about recursive self-improvement: a proof is only as good as the theorem that it proves. If the formal property being established is “wrong,” if it doesn’t line up with our informal intent, then we may be worse-off for the exercise of proof-writing and proof-checking, gaining a false sense of security. Here is a tour through three styles of specification, each representing one take among many in the field on what we really mean when we talk about “safety” of a library.
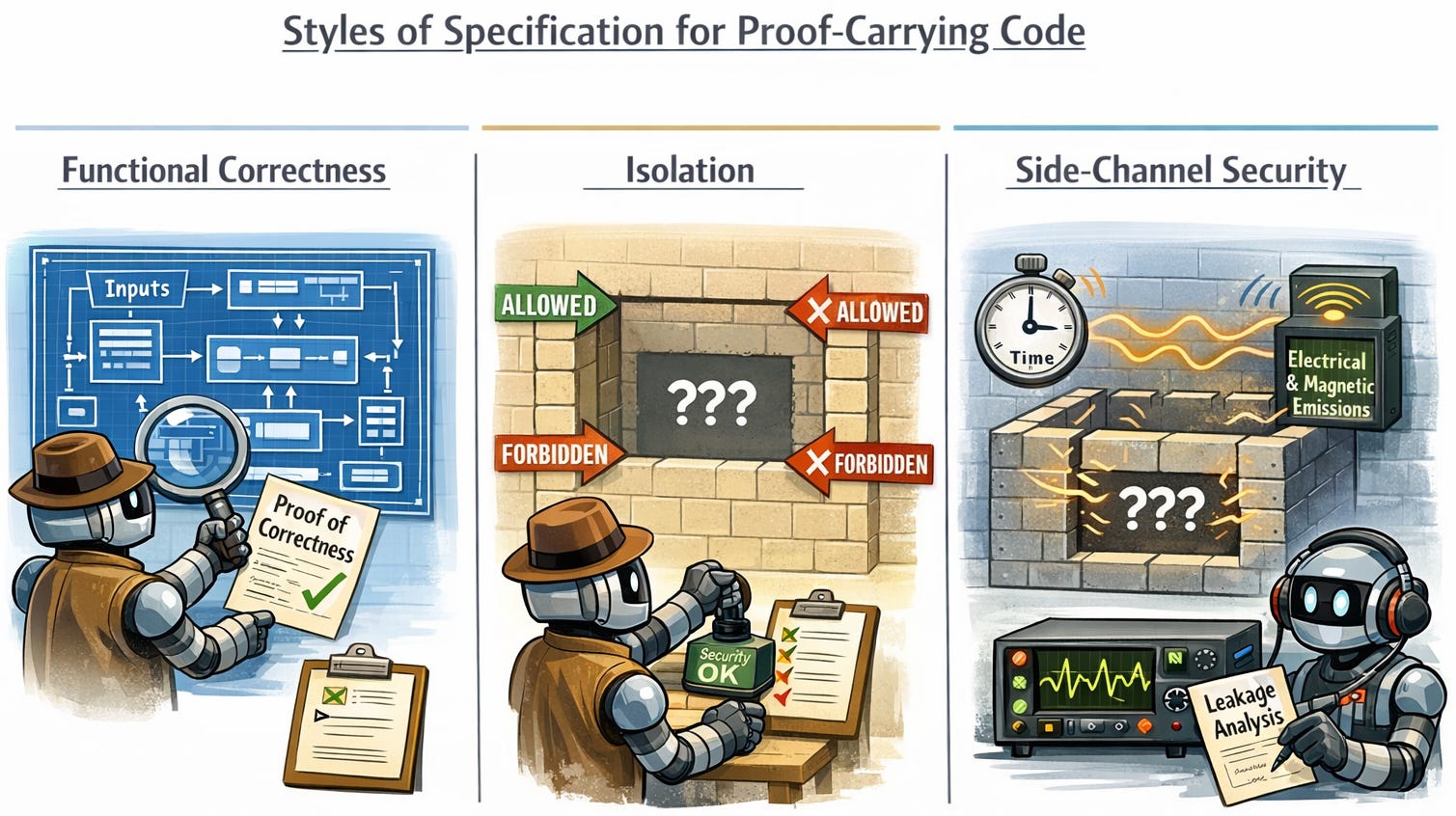
Functional correctness gets very specific about, for instance, exactly which mathematical function a library should compute. This style of specification often requires the most work, almost invariably involving significant extra work by the author of a library. A proof typically draws on insights about the code base that aren’t obvious even to other programmers.
Isolation specifications try to enforce merely that a library fits into a block diagram of a larger system in the expected way, not interfering directly in the operation of other components. One venerable isolation property is memory safety, which roughly has to do with proving that a software module only accesses the parts of a shared memory that we have explicitly given it references to. Most original work on proof-carrying code focused on this guarantee, tied to memory-safe languages like Java. A hot programming language today advertising memory safety is Rust, which supports such guarantees despite allowing relatively much flexibility to program intricate and speedy algorithms (at least so long as the programmer avoids the unsafe keyword, which does really stand out to a reader). The great benefit of safe languages is that, effectively, the programming-language implementation automates checking memory safety, up to a high level of rigor. The programmer has to include some extra hints in the code, most often phrased in terms of a type system, but these taken together tend to be much less verbose than mathematical proofs.
Side-Channel Security, which I introduced in the last post, deals with the reality that deployed systems don’t need to respect the clean boundaries that we see in system-architecture diagrams. Sometimes a security flaw in a library manifests in how the timing of a computation leaks secrets. More craftily, an adversary monitoring the electrical and magnetic emissions of a system may be able to learn a secret. I mentioned some of my recent work proving lack of timing side channels for hardware and software (compilers).
Nontrivial prototype verification systems have been built around all of these styles, but let me mention another critical ingredient. Though JavaScript on the web is itself a counterexample, very commonly software packages are written as source code in human-friendly language and then transformed into formats like machine code or bytecode by compilers. Even if a source program has been proved to meet a specification, a compiler bug could produce a lower-level version that no longer complies. That’s why the original work on proof-carrying code gave a taxonomy of two ways of closing this trust gap.
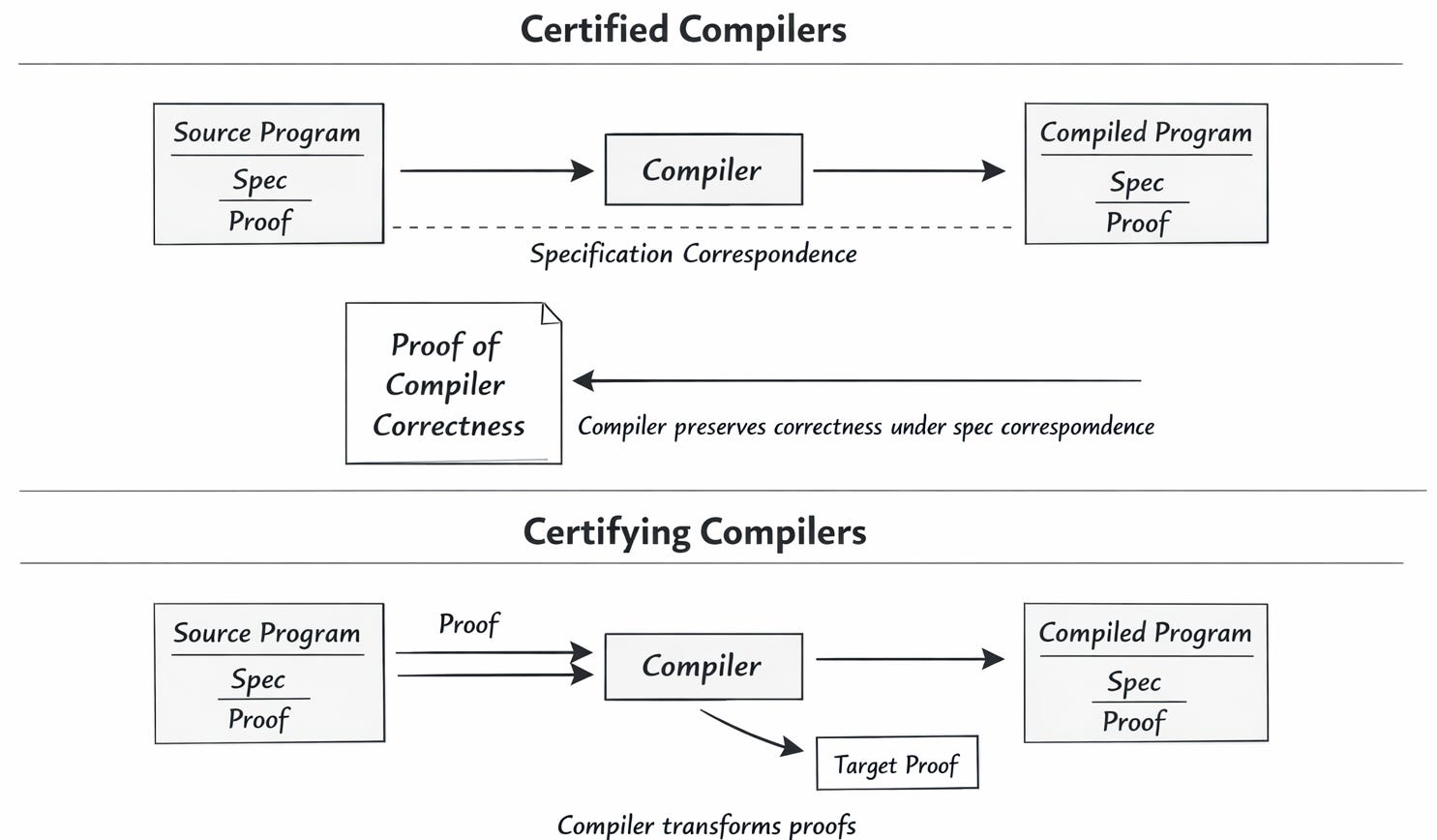
A certified compiler like CompCert is itself formally proved as correct, removing the risk of miscompilation. In contrast, a certifying compiler translates not just code but also its proof, creating a new proof that applies to the generated code. The contrast between them is similar to one that could, as a thought experiment, come up in hiring a contractor to build you a house. The equivalent of a certified compiler is a contracting firm that has gone through extensive certification, convincing experts that they only build top-notch houses. The equivalent of a certifying compiler is a contracting firm that delivers each new house along with blueprints and a justification document that experts can read to become convinced quickly that the house was built well.
Certifying compilers were first studied in the context of type systems, where one approach takes care to preserve type information from source programs all the way down to the assembly language (now typed assembly language). A program in that final language looks like one of the classic low-level languages of computer science, but it maintains type information that classifies parts of machine state with what kinds of values they may contain. The typed assembly program can be checked automatically by a relatively simple algorithm, with no need to trust anything about the source program or the compiler. I have some recent related work myself in the setting of cryptography and timing side channels.
Reflecting on this whole suite of techniques, what it adds to current mainstream thinking about software supply chains is going beyond just confirming that software came from the expected source. We instead receive strong mathematical guarantees even with no trust in the source of a software package. There are also clear advantages versus techniques like running untrusted code in sandboxes, special environments that limit interaction with the rest of systems. For one thing, it can be cheaper to run verified software, with no residual need for runtime monitoring. For another thing, sandboxing can neither establish functional correctness (in cases where we want that level of confidence in a module) nor typically block information leaks through side channels. It’s also true that, when a sandbox detects a program misbehaving, it often can only halt the program, an unpleasant surprise that we might avoid by proving in advance that a program behaves itself.
Conclusion
As in the last post, the top-level message here, now about the potential for agents who don’t trust each other to exchange code along with checkable proofs of its safety, is a mix of optimism (there is a large body of research work and nontrivial implementations) and warning (choosing the right specification is still hard). The dynamics of Neo learning kung fu in The Matrix may not be quite right, in a world taking these ideas to heart. There was dramatic value in requiring Neo to be plugged into the computer for a long time to learn kung fu, but we could probably help him (or at least an AI agent) pick it all up in an instant. In the moment after he snaps awake and before he says “I know kung fu,” he should run his proof checker first – which doesn’t interrupt the action because proof checking should be snappy.
More seriously, I do want to claim that this idea is a crucial enabler of a world where AI agents execute a distributed algorithm for pushing technology forward. Different agents can try out different approaches for idea generation and then sell their best outputs to others, even competitors with good reason to distrust them. The result is a global marketplace for agent self-improvement, retaining characteristics of our human economy but likely running at a much higher pace.
A few other technical tools, blockchains and deep learning, need to be considered for their roles in this future economy, and I’ll spend the next few posts on them.

Hi,
It's an interesting idea that proof-carrying code (PCC) could improve the safety of AI agents! The first time I heard about this was from Erik Meijer (see https://cacm.acm.org/practice/guardians-of-the-agents).
Regarding Functional Correctness, Isolation, and Side-Channel Security:
Functional Correctness: Are Lean 4 or Agda ideal candidates for writing AND proving code correctness in the context of your blog post? Both are a functional language and also an Interactive Theorem Prover (ITP), but the average developer 'only' knows Java, C++, etc. So we have a wide gap here! Or does it not matter anymore?
Isolation: To what extent can an OS like Linux be bent (via eBPF) to run AI-generated programs securely in kernel space?
Side-Channel Security: This might be economically too expensive, but could FHE chips like Intel's Heracles (https://spectrum.ieee.org/fhe-intel) just eradicate this whole field of side-channel security problems?
Thank you for your blog post!
Artur