
Why Software Requirements Get Easier in an AI Economy
Abstraction boundaries pay off

One of the best protections, in principle, against AI systems going off the rails during recursive self-improvement is formal verification, where we prove mathematically that systems meet formal requirements. A natural obstacle is being sure to write out in enough detail what rules we want to enforce, such descriptions being called specifications. An increasing role for AI in the economy can, on the one hand, increase the number of computer systems for which careful enforcement of rules is critical. However, there is a sense, perhaps ironic, in which the job of spelling out the right rules, of writing good formal specifications, becomes easier. I have made the case that, as AI proliferates, it makes sense to design the economy to include bubbles where AI interacts only with other AI, and I sketched how specifying user interfaces then becomes easier.
I will now make the case that the broader challenge of settling on system requirements also becomes fundamentally easier. The basic advantage comes from whose intentions need to be formalized in the requirements. Getting requirements out of squishy humans can be arbitrarily challenging, but what happens when the source of new requirements is overwhelmingly other programs already in production?
The Hard Part of Software Engineering
Even before AI coding assistants changed a software engineer’s mix of time spent on different activities, it was a truism in the field that the overwhelmingly time-consuming activity was understanding what users really want, or requirements-gathering. With recent automation of so much of routine coding, we might expect that the centrality of requirements-gathering will only increase. I want to suggest that, leaning even more into what will be possible with automation, we will ironically see requirements-gathering as we know it decrease in importance. To make that case, I should first review the conventional wisdom.
When programmable computers were first developed, the details of who did what to get them programmed were no doubt a little chaotic. Soon enough, though, around the 1960s, a split developed between analysts and programmers. The former had the job of understanding requirements and translating them into relatively unambiguous notation like flowcharts, which programmers could then translate into code. My own formal programming education involved just the slightest brush with flowcharting before that trend fully evaporated, but, in the course of a summer internship, I do remember being advised by a long-time technical employee of a large corporation that “programmer” was a poor choice of career path, representing a kind of cognitive underclass taking orders from analysts. (Perhaps developments in AI coding assistance make that advice more prescient than I realized at the time!)
The discipline of software engineering developed orthodoxies like the waterfall model, where teams are very careful to go through many iterations of written requirements before beginning the expensive process of programming. Writing the requirements is not just a process internal to a team of software specialists. Arguably most important is interfacing with the intended users of a program, to understand fully what functionality will satisfy them. One conversation is rarely enough. Instead, the intended users must be shown repeated revisions of a requirements document, to help them think more abstractly about the full range of relevant scenarios.
Eventually, waterfall went out of style in favor of agile methods, which focus on getting to working programs more quickly, so that users can give more-informed feedback. The problem is that even the software experts find it hard to enumerate all relevant scenarios for a complex program. Many scenarios only become clear as critical by relying on the expertise of the users, yet those users are not trained in the kind of abstract and systematic thinking needed to map out all relevant usage flows, with their steps and subtleties. Eliciting such information to guide a product roadmap remains so challenging today as to motivate the specialty of product management.
The challenge of learning what solution is really best for users is often explained using a quote attributed (perhaps apocryphally) to Henry Ford, about how if he had asked his customer base what they wanted in transportation, they would have asked for faster horses, not the cars that he eventually gave them. There are at least two separate problems. First, a user with a vague idea of the fundamental purpose of a piece of software may have trouble explaining that purpose in enough detail. Second, a user without an understanding of software-development pragmatics may not understand what is feasible to build at what cost.
The good news is that these challenges should diminish dramatically when the users asking for functionality frequently aren’t human. More precisely, the old kind of requirements-gathering challenges remain, perhaps even in a more challenging form, for a minority of the parts of an agent ecosystem, while this activity can largely be avoided for the remaining parts.
Software as a More Knowable User
There is a fundamental reason why it is easier to know what a program “wants” than what a person wants. Our evolutionary journey hasn’t placed much selection pressure on human minds to be easy to model by others. In fact, aspects like signaling have even promoted opacity of our thought processes, say to make it harder for others to figure out what will impress us, so that we can believe that the ones who do succeed at impressing us are unusually competent and worthy of affiliating with. In contrast, a program needs to be explainable to at least one audience: the computer that runs it! That is, the computer needs to have a clear-enough sense of the program meaning to be able to run the program, which we can phrase more technically as a need for programs to have unambiguous semantics. Add on top the need (at least until quite recently) for humans to understand the program as they are writing and maintaining it. There has been plenty of selection pressure for programs to be understandable, which can now pay off in their ability to request writing of new code to help them do their jobs better.
The ultimate setting for this advantage to shine is where significant pockets of the economy include only AI interacting with more AI, rather than with humans. Such a setting can maximize the benefit of environments designed for legibility to automated reasoning. An ecosystem of automated work can recursively self-improve toward a specification set in advance, or a set of competing and cooperating agents can evolve together toward their own specifications. Either way, we have an easily machine-readable characterization of fundamental goals, which can periodically be projected into requirements for new programs.
The next drawing illustrates the principle more visually. The left panel shows the world more as it is today, including many AI agents, almost all of which have to coordinate directly with humans, forcing the gathering of requirements from stakeholders who aren’t great at explaining what they want. The right panel shows the world we may be headed toward, where most of the economy is handled by AI agents, who naturally form into clusters with only rare gatekeepers who need to interface with humans. The interiors of the clusters are places of order and clear requirements. In this world, the great majority of programs are interior and benefit from clear sources of requirements.
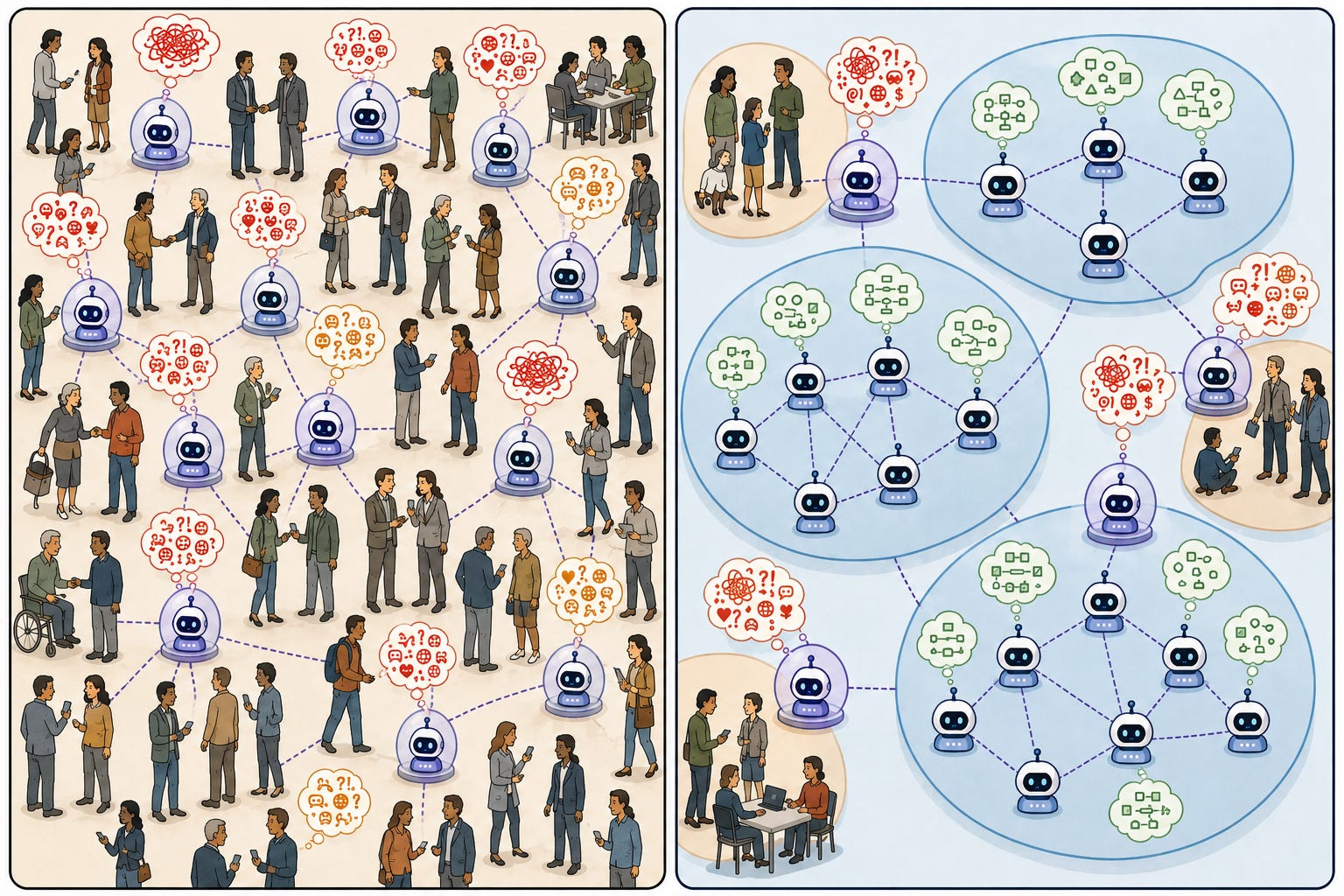
It is critical that we will not be coming along later and trying to characterize the behavior and desires of agent ecosystems. There is the potential now to weave formal specification and verification into their design from early days. Our challenge becomes writing a specification covering the whole AI ecosystem, forcing the inhabitants to evolve in ways compatible with our goals and values. This requirements-gathering challenge remains at least as hard as usual! My point is that many other engineering projects within such AI bubbles become easier to frame, and they should become the majority of ongoing software-engineering effort (and source of associated cost).
A more modest version of this phenomenon is already common today. Take the example of a software-engineering team implementing a new web browser. Existing technical standards significantly constrain the new design. There are already voluminous requirements written down in Internet standards, explaining how the code for a web page corresponds to what should be displayed to the user. As more of the economy is handled by AI agents, more of their contexts will be standardized similarly or at least embodied in existing code that could be analyzed.
It is worth noting here that the most popular kind of AI software today, deep learning, has the distinct disadvantage that individual programs (now construed to include learned elements like model weights) have little apparent structure and thus are difficult to understand, say to figure out “what they want.” I would argue this quality should push us toward more use of other methods designed for understandability and ability to bound their behavior precisely with mathematical arguments, though my broader argument remains relevant otherwise. Put another way, we may have a short window to decide if we want to live in a world of inscrutable learned systems or instead push for systems proved to meet explicit requirements. It may be that the second path is critical not just for safety against rogue AIs but also for the efficiency of AI self-improvement that it enables, even if the ultimate goal happens to be better targeting of online ads. Let me now explain the source of that efficiency.
Copying Parts of Your Own Specification and Code is Relatively Easy
Let’s get a bit more specific about how the earliest stages of software engineering get cheaper, as we get programs asking for the writing of new programs.
Assume first that the user programs have been written following good practices and have their own polished requirements documents. We can even look to the most general version of an argument, assuming that the programs that will ask for new programs have their own requirements written out to the standards of quality desired for the new programs. The glib explanation of the advantage, then, is that we can just copy relevant bits of requirements content out of the requirements for the users requesting the new programs. No such option is straightforward for human users, who tend not to publish their life goals comprehensively in machine-readable form.
Consider more broadly how it should happen that programs want to see new programs written. I have suggested that we see an economy engaged in technical innovation as a distributed system in the computer-science sense, with different agents cooperating and competing within a set of overlapping optimization problems. Different participants know at different levels of detail what they are trying to accomplish; the participants that are software should be especially likely to be associated with rigorous formal specifications (or at least, that honor is unlikely for the people!). At some level, such an economic system is a program engaged in repeatedly optimizing itself.
Let’s get more specific with an example where a self-improving program naturally persists some of its own code into an improved variant. The relatively straightforward case is a program for computing a particular mathematical function and for noticing ways to improve its own structure to compute that function more efficiently. I’m arguing that software-engineering projects spinning up in the future will look more like this kind of self-optimization than like what we’re used to. A program with a goal but only a relatively fuzzy idea of how to achieve it will ask for new programs to be written that aim at the same goal but with more specific strategy. A good if fairly technical analogy is to multi-stage programming, which I’ll explain by example (though most of the code details aren’t critical to follow). Here is a (recursive) Python function that raises number x to the power of n.
def power(x, n):
if n == 0:
return 1
elif n % 2 == 0:
y = power(x, n // 2)
return y * y
else:
return x * power(x, n - 1)Imagine that an AI agent uses this function frequently for exponentiation tasks. In fact, it notices that half of the uses have n of 13. Through a mechanical process known as partial evaluation, it produces this specialized version.
def power13(x):
x2 = x * x
x3 = x * x2
x6 = x3 * x3
x12 = x6 * x6
x13 = x * x12
return x13We had one stage of computation to come up with this code, and now we can run the new code repeatedly in a later stage, hence the name “multi-stage programming.” The new power13 function can run more quickly than power (it doesn’t need to run all of those tests about arithmetic properties of the exponent; it doesn’t need to do bookkeeping about how a group of function calls relate to each other). Part of what we give up to gain that speed is the generality of the function, but we can imagine we keep around the old version, too. We still use up extra storage for specialized versions, and we still spent time to come up with them. The same tradeoffs apply to just-in-time compilation as practiced by web browsers for efficient execution of the code embedded in web pages.
My claim, now more technical, is that these examples from mainstream computing today are more representative of the future of software development than are classic software-engineering projects. Yes, new projects will still be started to build software with human users, in which case the classic problems and methods remain relevant. However, for efficiency reasons, more and more of the economy will be handled by AI agents with no direct connections to humans, only other AI agents. Agents and groups of agents will trigger new software development for the same reasons it paid off to specialize the power function above, but these projects will be relatively better-defined, with their specifications naturally derived, often in mechanical ways, from the specifications or at least code of the requesting agents.
The next image tries to illustrate the pattern, with an agent requesting a new program based on a subset of its own code or specification, plus a novel environmental stimulus that the code should now be specialized to.

Previous posts have involved similarly geeky analogies based on interpreters, programs that run programs in particular languages; and compilers, programs that translate programs between languages. At some level, an agent could operate indefinitely as an interpreter. It has some high-level mission with a lot of execution details to figure out, through some kind of search process, perhaps coordinating with others. It can accumulate notes on wisdom gained so far, which are repeatedly consulted by code written to be prepared to act properly on whatever notes are passed to it. However, as the search proceeds, some parts of the code are revealed as irrelevant. Some are revealed to contain significant handling of uncommon or irrelevant cases. With a complex-enough initial program standing for everything that goes into doing a job somewhat like those done today by highly trained professionals, all sorts of software-engineering projects can be seen as specializations of that initial program. The possible scope is even wider as we imagine communities of agents coordinating to kick off software projects.
Conclusion
The argument I’ve spelled out here fills out a three-point recommendation or prediction for how we’ll take advantage of automated intelligence.
Formal verification is an invaluable tool for processes that search for better software, allowing up-front confirmation that a program will behave as intended in a variety of circumstances. However, we need sufficiently precise specifications to make formal verification meaningful.
If we do manage to kick things off with precise and comprehensive specifications for computer systems, then the searches they coordinate for better software can naturally pass on that specification quality toward the development of the new programs.
With that kind of recursive self-improvement loop operating well, it pays off to find ways to cloister units of economic activity away from sources of specification complexity, allowing them to have simpler specifications that enable the search process to operate effectively.
Such a loop depends critically on the efficiency of its implementation. The faster it runs, and the more it can do with a given amount of memory, the more effectively we can find better new strategies, which pays back recursively in the system’s ability to keep improving itself. That concern motivates thinking carefully about what software of the future should look like, as I’ll now cover in a series of posts about design of programming languages. I’ll make the case that the same principles that will aid autonomous systems also make sense for human programmers. I’ll also argue that languages like Rust, often held up as exemplars of the future of programming-language design, are not cut out for the performance scaling we’ll need for important applications.
I have some experience with very large-scale projects within major corporations.
Specifications were created by staff in customer-facing roles and subsequently stored in large databases. These specifications were then broken down into detailed requirements. Over time, the volume grew to the point where there were thousands of individual requirements.
Although the development process mandated a thorough review of all requirements, human errors still occurred. Furthermore, additional requirements were frequently introduced during the development phase itself.
All of this resulted in a requirements database that lacked full consistency—regardless of whether the Waterfall model or Agile Development was being used.
Here is what I would like to see:
a) Requirements management tools should check natural language text for consistency right from the start and immediately alert users to any inconsistencies found in the database.
b) The process of breaking down high-level requirements into detailed ones should be AI-assisted, with the AI specifically flagging any gaps—essentially signaling, "Something is missing here!"
c) Existing requirements in commercial tools like e.g. IBM DOORS or Siemens Polarion should feature a new mode allowing users to resolve database inconsistencies through a dialogue with the AI.
d) Official bodies—such as the IETF, SAE (automotive), ERA (railway), and many others—should check their existing specifications for consistency and gaps. New specifications (typically involving multiple companies) should be developed in collaboration with AI.